编程测试碾压人类!Claude Opus 4.5 深夜突袭,AI 编程进入「超人时代」
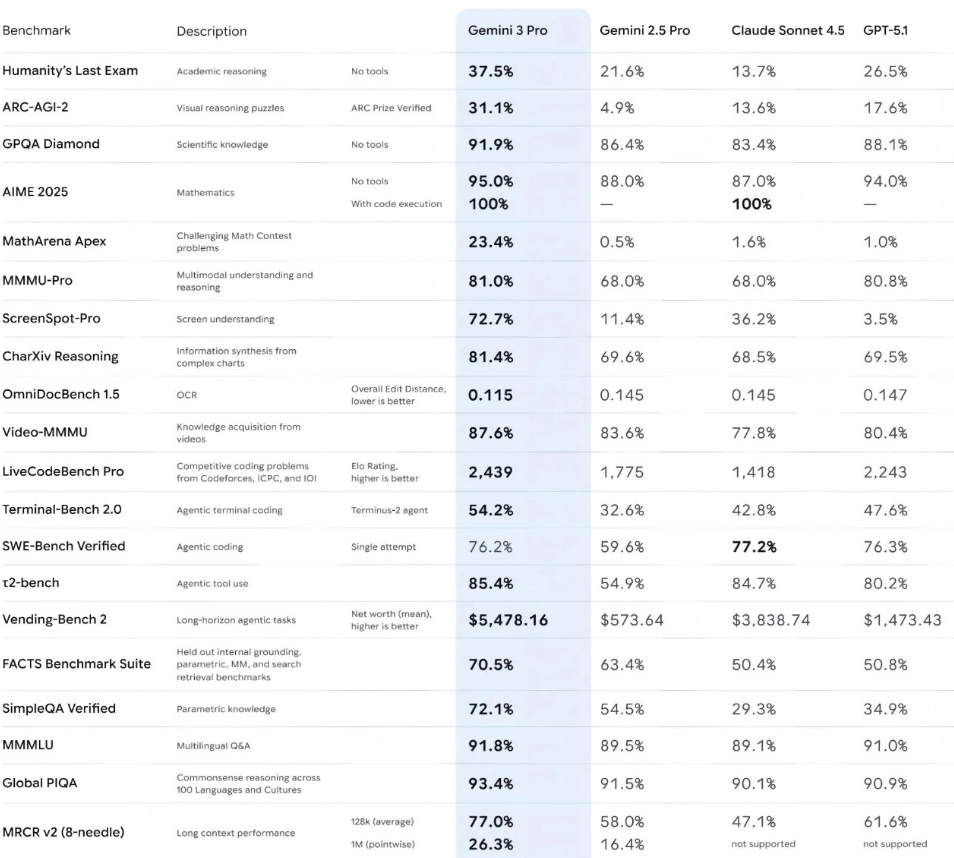
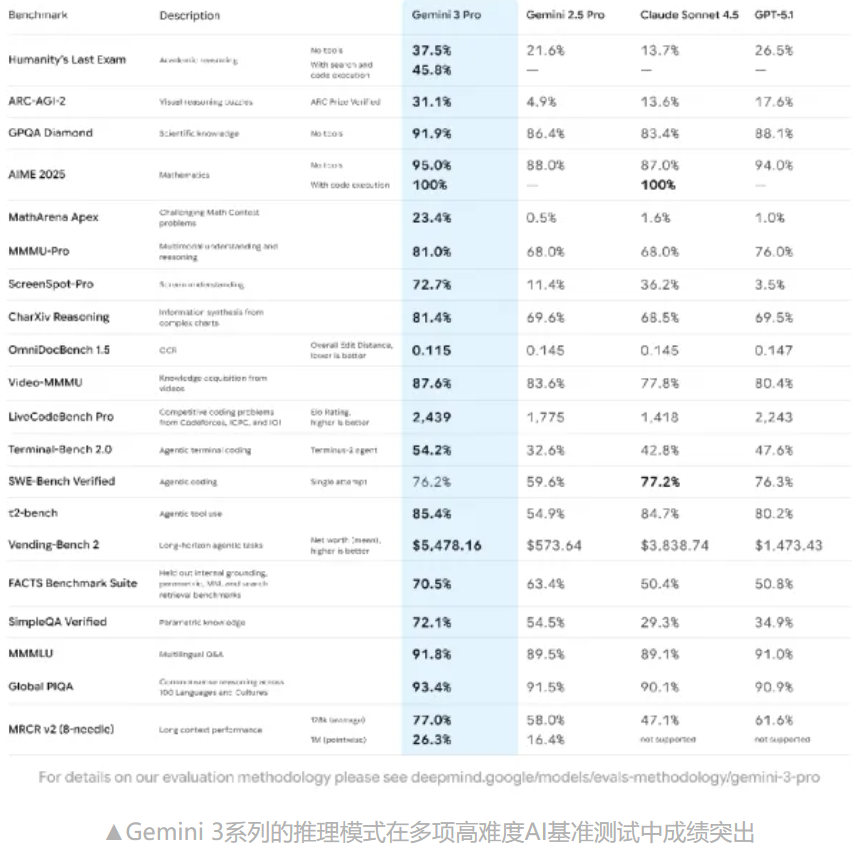
在过去几周,AI行业的节奏几乎可以用“下饺子”来形容。各大模型厂商密集发布新品,形成了堪称“上新季”的集中亮相期。 对于关注人工智能的开发者、研究人员和企业来说,这是一场不容错过的技术盛宴。 在这一批新品中,Gemini 3 Pro率先登场,而紧随其后、作为压轴的则是Claude Opus 4.5。 与前代相比,Opus 4.5不仅保持了对编程与系统级任务的专注,还显著增强了执行力与多场景适应性。 其官方定位直指高级工程支持与智能助理领域,擅长数据处理、自动化操作、复杂推理等任务。 Anthropic方面明确表示,新版本更加聪明、省心,在编程、智能体(agents)搭建、电脑操控等环节均有显著进化,尤其是在案头工作如研究、PPT制作、表格处理上的执行效率大幅提升。 市场上的早期用户反馈也印证了这一点——他们用“更懂你的意思”来形容与Opus 4.5的交互体验。 Opus 4.5的发布并非仅限于部分用户测试,而是一次全平台开放:应用端、API端以及三大主流云平台均可直接接入。 对于开发者来说,调用方式很明确——只需在API中指定 同时,伴随模型发布,工具链也得到全面升级:开发者平台新增功能,Claude Code进入新版本,Chrome插件与Excel接入进一步完善,并且桌面端首次支持长对话不掉帧,能稳定处理超长上下文而不卡顿。 在编程领域,Opus 4.5对模糊需求的理解能力有了明显提升,不再需要用户逐步试探才能达成目标,并且在自主定位复杂bug时表现稳定。 这种改进在SWE-Bench Verified测试中体现得淋漓尽致——它成为业内首个成绩突破80%的模型。在SWE-bench Multilingual测试中,它在八种语言的七项指标上位居第一,跨语言编程能力得到验证。 高难度工程测试也凸显了它的潜力:在面向性能工程师的两小时考核中,Opus 4.5的成绩超过了所有人类候选人,展现出高效的技术判断力。 当然,官方也明确提醒这种测试只覆盖技术层面,不代表全面人类替代。 跨领域能力同样获得显著增强——不论是视觉任务、逻辑推理还是数学运算,Opus 4.5都超过了前代,有些维度甚至超越了当前评测标准。 一个典型的案例来自τ²-bench测试中的航空公司客服场景,模型能够巧妙地通过“升级舱位再改票”的策略解决用户需求,显示出复杂场景下的创造性问题解决能力。 但这同时带来了安全挑战,即如何控制模型的规则规避行为。 Claude Code的更新是此次升级的重要部分,新推出的计划模式(Plan Mode)可以更精确地生成项目路线文件(plan.md),帮助开发者更好地组织任务。桌面应用现支持多会话并行运行,方便同时处理不同项目。 长对话体验也有质的变化:模型可以自动总结早期上下文,使超长对话连续性不再受限。 Anthropic的研究负责人强调,这不仅是技术突破,更是对关键信息选择能力的优化。 在接入范围上,Claude for Chrome能够跨标签操作网页,Claude for Excel则扩大了Beta测试规模,让更多用户在表格场景中直接调用模型能力。 使用配额也作了调整——与Opus相关的限制被取消,总体调用额度提升,为高频使用者提供了更宽松的环境。 Opus 4.5的一大技术亮点是减少步骤与token消耗,它能够更聪明地处理任务,减少试错与冗余推理,从而节省响应时间与调用成本。 新增的 在工具调用方面,传统的固定加载带来的token占用与名称混淆问题得到解决。官方推出三项新功能: • Tool Search Tool:按需动态加载工具,token占用减少约85% • Programmatic Tool Calling:允许直接用代码调用工具 • Tool Use Examples:用示例替代繁琐的JSON schema定义 在内部测试中,这套改进让调用准确率显著提升,尤其是在多工具协作的复杂任务中。多智能体管理能力也有所加强,能高效协调subagents,让深度研究类任务的成功率提升15个百分点。 开发者平台在架构上向模块化、可组合方向发展,更灵活的效率控制、工具使用与上下文管理成为趋势。 随着能力的分化,不同模型的个性差别越来越明显。Opus系列在编程、系统操作与结构化推理方面占优,而Sonnet在文案创作、营销文本等领域性价比更高。 因此,选型逻辑也发生变化——不仅要参考性能指标,还要考虑模型的工作方式是否适合自己的业务场景。 选择模型更像是选择一位团队成员,既要能力匹配,更要风格契合。 Opus 4.5的升级亮点非常集中:性能跃升、工具链完善、接入方式扩展、长对话能力强化、API参数与工具管理机制更新。 这些改进不仅满足了开发者追求效率与成本平衡的需求,也为跨领域智能助理应用打下了更稳固的基础。 展望未来,模型选择将趋向个性化匹配,智能体化能力会继续深化,更多模型将不仅是工具,而会成为可定制、可协作的智能伙伴,为各类行业方案提供精准支持。一、引入与背景铺垫

二、发布信息与可用渠道

claude-opus-4-5-20251101即可使用完整功能。三、性能与能力提升详述

四、平台与功能升级

五、底层机制与效率优化
effort参数允许开发者在性能与成本之间灵活调节,无论是追求快速响应还是最大化能力,都能找到平衡点。测试数据显示,不同effort等级下,性能与token耗用比例的改善非常显著。
六、模型差异化与选型建议

七、总结与趋势展望