Gemini 3.0 Pro模型卡曝光,多模态、知识库能力大幅超越GPT与Claude
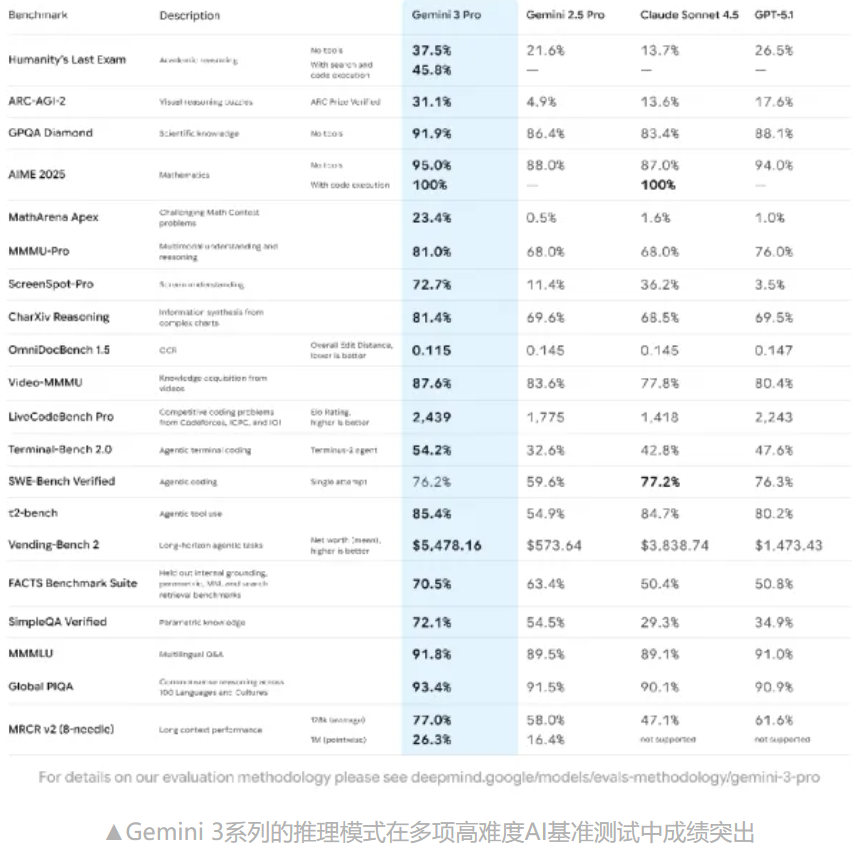
在AI大模型竞争白热化的当下,谷歌即将发布的Gemini 3.0 Pro无疑是业界最期待的事件之一。 根据最新的泄露信息和性能指标,我们可以清晰地判断:Gemini 3.0 Pro绝非一次小修小补的迭代,而是标志着谷歌AI能力的一次整体跨越。 它在多模态理解、深度推理以及长上下文应用等核心领域均展现出显著的突破,重新定义了AI Agent的潜能。 Gemini 3.0 Pro的核心能力升级,着重解决了现有大模型在“理解”和“应用”层面上的痛点。 多模态能力已成为旗舰模型的基础配置,但Gemini 3.0 Pro的突破点在于对视频内容的深度理解。模型不再满足于识别视频中的静态图像或简单的物体,而是能处理时间维度上的复杂信息。 • 性能指标突破:在“Video-MMMU”这一严苛的视频理解基准上,Gemini 3.0 Pro得分高达约 ,显著高于其主要竞争对手GPT-5.1的约 。 • 核心能力体现:这种高分体现了它能够: • 分析人物动作的连续性:理解人物在视频中的意图和行为逻辑。 • 推断前后因果关系:根据视频片段预测后续发展或追溯事件起因。 • 理解场景语境:综合画面、声音、动作来判断整个事件发生的背景和意义。 这意味着Gemini 3.0 Pro在向真正“看懂视频”、理解动态世界迈出了决定性的一步,为视频分析、内容审核和智能监控等应用开启了新的可能性。 深度推理和解决复杂问题的能力,是衡量通用人工智能水平的关键标准。Gemini 3.0 Pro在这方面表现出顶尖水平。 • 高难度数学性能:在允许调用代码执行的条件下,模型在AIME等高难度数学测试中取得了约 的得分,接近人类顶尖选手的水平。 • 推理链的稳定与完整:新模型生成的推理链条更加完整和稳定,在处理图文混合输入时的逻辑判断也更为准确。 • 用户体验:从用户早期评价来看,模型在处理复杂、多步骤问题时“更像在思考”,而不是简单地检索和拼凑信息,体现了其对知识的深层掌握和运用。 长上下文窗口不再是单纯追求数量的游戏,Gemini 3.0 Pro将其带入了实用化阶段。 • 窗口规模与原生支持:泄露资料显示,模型支持长达 token的上下文窗口,并且是以**“原生多模态”**的形式支持(即文字、图像、视频、音频信息可以在同一超长窗口内被处理)。 • 实质改进:对比前代模型,Gemini 3.0 Pro的改进集中在质量而非长度: • 在处理超长文档时,对关键信息的丢失率显著降低。 • 跨段落、跨文件、跨模态的信息整合能力更强,能真正进行复杂的知识推理。 • 在长文本场景下的幻觉率显著下降,输出更可靠。 这一改进标志着长上下文窗口从“能读长文本”升级为“能对复杂知识进行深度推理”。 对于AI Agent而言,编程与工具调用能力是执行任务的基础。Gemini 3.0 Pro在这一领域展现出全能型选手的定位。 • 整体优异表现:在LiveCodeBench、SWE-Bench等主要的编程和代码理解测试中,Gemini 3.0 Pro的整体表现优于前代,执行更稳定,响应更可靠。 • 均衡定位:尽管在SWE-Bench Verified等专项测试中,Claude 4.5等竞争对手仍可能略有优势,但Gemini 3.0 Pro的价值在于其全面而均衡的能力,能够在绝大多数编程和Agent任务中提供高水平的、可靠的服务。 Gemini 3.0 Pro所展现出的数据具有极强的说服力,特别是其在视频理解和长上下文推理上的突破,预示着AI Agent的能力边界将再次被拓展。 然而,作为一名科学严谨的技术分析师,必须提醒读者: • 数据来源限制:目前的核心成绩主要来源于非官方的泄露资料和测试环境,尚未获得谷歌官方的全面验证。 • 实装验证:公测环境中的用户反馈相对有限。模型在基准测试中的理论性能,与在海量并发、复杂多变的用户“实装”环境中的表现,可能存在差距。 总而言之,尽管数据指向一个令人振奋的结论——Gemini 3.0 Pro实现了能力的整体跨越,但其最终的行业影响力,仍需等待正式发布后的全面验证。
一、 核心升级点详解
1.1. 多模态:真正理解视频内容(超越“看图”)
1.2. 推理、数学、知识库能力显著提升
1.3. 长上下文能力更实用化(1M token与原生多模态)

1.4. 智能体与代码能力全面而均衡
二、 总结与注意事项