GLM-4.7实战指南:三个梯度测试,解锁国产大模型的代码生成与审美上限
摘要:国产大模型 GLM-4.7 在 Agentic Coding 与前端代码生成领域展现出惊人实力。本文通过梯度式实测,对比 Claude 3.5 Sonnet,深度解析其在逻辑推理、UI 审美与交互体验上的突破,附赠高阶 Prompt 技巧。
01. 开篇:这一次,不仅是参数的胜利,更是「体感」的质变
如果我不说,你可能很难相信,眼前这个带有失焦光斑背景、打字机动效、且交互极其丝滑的网页,完全是由一个国产 AI 模型在 30 秒内“手搓”出来的。
没有复杂的 CSS 调试,没有反复的样式修正。
长期以来,在 AI 辅助编程(尤其是前端代码生成)领域,Anthropic 的 Claude 3.5 Sonnet 一直是开发者心中的“白月光”。它写出的代码不仅 Bug 少,而且审美在线。

而大多数国产模型,虽然参数跑分在 Benchmark 上卷得飞起,但一到写页面,往往不仅逻辑容易“翻车”,审美还停留在十年前的 Bootstrap 时代——充斥着廉价的配色和僵硬的布局。
但 GLM-4.7 的出现,似乎打响了反击的第一枪。
核心结论先行:
经过我长达一周的高强度实测,GLM-4.7 标志着国产 AI 模型在 “Agentic Coding” (智能体编程) 和 “前端审美” 上正式进入世界第一梯队。
它不再仅仅是一个“能用”的工具,而是一个在交互体验和视觉审美上能与 Claude 3.5 Sonnet 掰手腕,甚至在某些中文语境下表现更优的 “最强平替”。
02. 模型画像:GLM-4.7 强在哪里?
在进入实测之前,我们先快速过一下 GLM-4.7 的技术底色,建立对它能力的认知锚点。
什么是 Agentic Coding?
GLM-4.7 的核心卖点在于 Agentic(智能体化) 能力。传统的 AI 编程是“你问我答”,是一次性的文本生成。而 Agentic Coding 赋予了模型像人类程序员一样的反思能力:
• 它能自己浏览网页、查询文档。
• 写完代码后,它会自己运行环境进行测试。
• 遇到报错,它会自我纠错(Self-Correction),而不是把乱码扔给你。
这一能力的提升,让它在处理复杂逻辑任务时的可用性大幅提升,直接对标 OpenAI 的 GPT-4o 和 Anthropic 的 Claude 3.5。

硬核参数与性价比
GLM-4.7 延续了国产模型一贯的“量大管饱”策略:
• 超长上下文(Context Window):支持极长的 Token 输入,这意味着你可以把整个项目文档扔给它,让它基于全局理解来写代码。
• 思维链(CoT)增强:在处理数学和逻辑推理时,表现更加稳健。
• 价格优势:相比于美元计费的海外模型,GLM-4.7 的 API 调用成本极具竞争力,对于高频使用的开发者来说,这直接决定了能否大规模落地。
03. 梯度实测:从 SVG 绘图到复杂交互游戏
数据只是一方面,体感才是真的。为了验证它的真实水平,我设计了三组难度递增的测试,拒绝“云评测”。
Round 1:基础图形审美(SVG 生成)
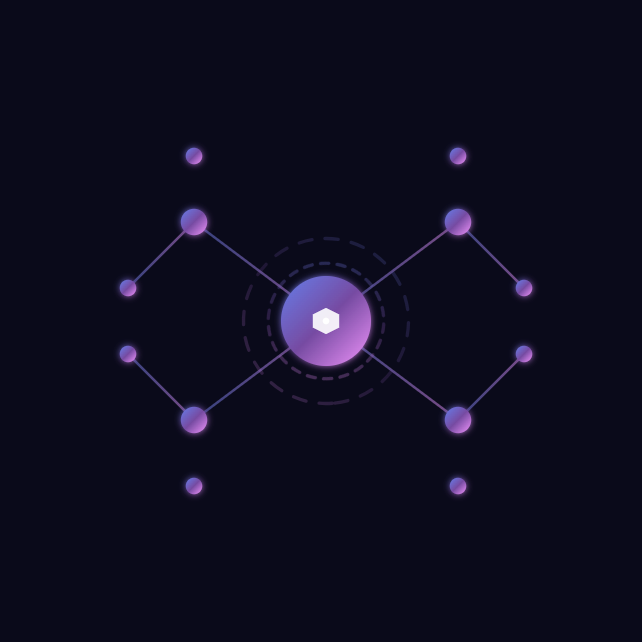
测试题目:“请帮我生成一个极简风格的科技感 Logo,使用 SVG 格式,要求体现 AI 与连接的概念,配色要高级。”
结果展示:
GLM-4.7 秒出代码。渲染后,我看到的不是那种粗糙的几何堆砌,而是使用了渐变填充和透明度叠加的精细图标。线条流畅,配色采用了深蓝与青色的冷调组合,非常有 SaaS 产品的现代感。
点评:在“听懂人话”并转化为“视觉语言”这一步,GLM-4.7 没有出现国产模型常见的“理解偏差”,审美直逼设计师初稿。
Round 2:交互逻辑与物理引擎(网页游戏)
测试题目:“写一个网页版的射击游戏,要有重力感应,子弹要有 biu biu 的音效,敌人被击中要有粒子破碎效果。”
这一关主要通过 JavaScript 考察逻辑能力。
• 代码完整度:一次生成,直接运行,无致命报错。
• 细节还原:它真的加上了简单的音频合成代码,按空格键时不仅有子弹射出,还有清脆的音效。
• 缺陷:坦白说,在复杂的粒子破碎效果上,物理计算稍微有点卡顿,且偶尔会出现判定 Bug(比如敌人被击中后没有立即消失)。
点评:虽然有小 Bug,但瑕不掩瑜。这种能将“逻辑(JS)”与“表现(Canvas)”结合得如此紧密的能力,通常只有 GPT-4 这个级别的模型才能做到。

Round 3:终极审美测试(个人介绍页)
这是本次评测的重头戏。我要求它模仿 Apple 官网 或 Teenage Engineering 的工业设计风格,制作一个个人主页。
Prompt 核心指令:
“不要出现应用商店那种廉价的卡片设计。我要克制感,使用大面积的留白。鼠标光标要换成霓虹绿的小圆点,背景要有缓慢浮动的暖金色失焦光斑。文字出现要带打字机效果。”
实测效果:
GLM-4.7 给出的代码让我感到震撼。
1. 视觉:它使用了 CSS
backdrop-filter实现了高级的毛玻璃效果;背景的光斑流动非常自然,没有任何割裂感。2. 交互:鼠标移动时,那个定制的“霓虹绿圆点”不仅跟手,还带有轻微的惯性延迟,高级感拉满。
3. 排版:字体间距(Letter-spacing)和行高(Line-height)调整得恰到好处,完全跳出了默认样式的俗套。
点评:这种“零 AI 味”的设计感,是我在 Claude 3.5 之外第一次在其他模型上体验到。它懂得了什么是“克制”,什么是“高级”。

04. 为什么它能做好?Prompt 逆向拆解
很多时候,你觉得 AI 笨,是因为没“调教”好。想要达到上述效果,除了模型底子好,Prompt 的设计逻辑也很关键。这里分享我的独家 Prompt 策略:

1. 设定审美参照系:
不要只说“好看”,要说“像 Apple 一样克制”、“像 Linear 一样极简”、“像 Teenage Engineering 一样具有工业感”。具体的参照系能瞬间对齐模型的审美标准。2. 细节描述具象化:
❌ 错误示范:“做一个很酷的背景。”
✅ 正确示范:“背景使用深色噪点纹理,叠加缓慢移动的 CSS 径向渐变(Radial Gradient)光斑。”3. 拒绝默认样式:
在 Prompt 中明确加入:“禁止使用默认的 Bootstrap 风格,禁止使用高饱和度的纯色,所有阴影必须柔和且多层叠加。”
05. 总结:国产 AI 的“当打之年”
回到文章开头的问题:GLM-4.7 是 Claude 3.5 Sonnet 的平替吗?
我的答案是:绝对是,甚至在某些维度已经是“上位替代”。
在纯粹的逻辑推理深度上,或许 GPT-4o 依然略胜一筹;但在前端代码构建、UI 审美理解、以及中文语境下的语义交互上,GLM-4.7 已经展现出了惊人的统治力。
对于开发者、设计师乃至想用 AI 快速验证想法的产品经理来说,GLM-4.7 提供了一个低门槛、高上限的选择。它不再是一个需要你反复修 Bug 的“半成品生成器”,而是一个能真正理解“美”与“逻辑”的全能编程助手。
📌 行动建议
• 对于开发者:可以尝试将 GLM-4.7 接入 IDE 插件,作为副驾驶(Co-pilot)使用。
• 对于普通用户:去智谱清言或其他集成平台体验一下它的“网页生成”功能,感受一下什么叫“一句话生成 App”。
国产 AI 卷到这个程度,作为用户,我们无疑是最大的赢家。
(本文评测基于 GLM-4.7 最新版本,实际体验可能随模型更新有所变化。)

说到这里,AI 的价值,应该是深入具体的业务场景,转化为实实在在的生产力。
无论你是想在 Cursor / VS Code / Claude Code / CodeX / Gemini CLI / Trae中加速代码开发编程,在 Obsidian / Notion 中构建私有知识库,还是通过 Chatbox、沉浸式翻译、Cherry Studio 优化日常工作流,以及制作宣传视频,生图创意设计,论文编撰,灵芽API 都能提供稳定靠谱的底层支撑。
作为国内领先的大模型 API 中转站,灵芽API 完美兼容 OpenAI 接口格式,支持官方直连,高稳定可靠,账单清晰透明。
如果你恰巧需要一个低成本、高可用的方案,让 Agent 和 AGI 真正融入你的项目与工作流,不妨从这里开始。
🔗 体验传送门: https://api.lingyaai.cn