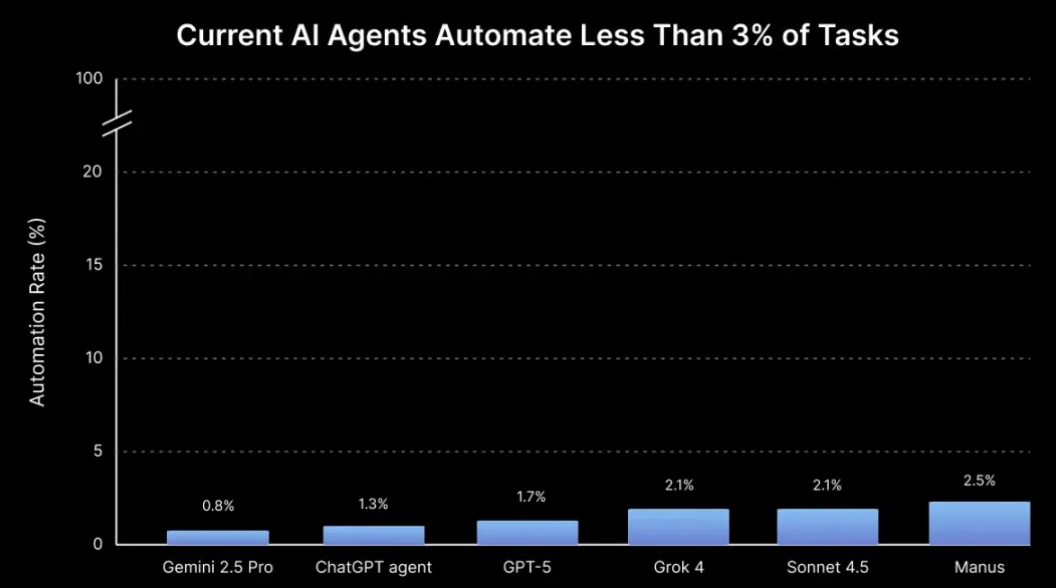
OpenAI 突然“自废武功”?砍断 99.9% 神经连接,只为看清 AI 到底在想什么
在当下的 AI 军备竞赛中,所有人都像疯了一样追求“更大”——万亿参数、千卡集群、海量数据。然而,OpenAI 最近悄无声息地反其道而行之,开源了一个仅有 0.4B(4亿)参数的小模型。 这个参数量在 GPT-4 面前连“孙子辈”都算不上,但它却在技术圈引发了比万亿模型更剧烈的地震。原因在于它的权重矩阵极度反常:99.9% 的数值被强制归零,仅保留了 0.1% 的有效连接。 这不仅仅是模型压缩,这是 OpenAI 推出的一项名为 Circuit Sparsity(电路稀疏性) 的底层技术变革。他们仿佛在复杂的神经网络大脑中进行了一场精密的外科手术,剪断了所有冗余的神经突触。 为什么要这么做?因为我们受够了 AI 的“黑箱”。 作为从业者,我们必须诚实地面对一个尴尬的科学事实:Transformer 架构极其强大,但也极度混沌。 在传统的稠密 Transformer(Dense Transformer)中,每一次推理,输入向量都会与巨大的权重矩阵进行全连接运算。这种计算模式带来了一个严重的科学问题——多义性(Polysemanticity)。 • 现象: 单个神经元往往并不是对应具体的概念(比如“苹果”或“红色”),而是同时响应成百上千个毫无关联的特征。 • 后果: 就像一碗缠绕在一起的意大利面,你抽动其中一根,整个碗里的面条都会动。当你试图解释为什么 AI 会产生幻觉(Hallucination)时,你面对的是数亿个这种纠缠不清的参数,根本无法追踪逻辑源头。 根据 Anthropic 等机构的“叠加假说(Superposition Hypothesis)”,神经网络为了在有限的维度里存储无限的特征,会将不同的特征通过线性组合“折叠”在一起。这虽然极大提升了效率,但彻底牺牲了可解释性。 而 OpenAI 的 Circuit Sparsity,就是为了打破这种叠加,强行把“面条”理顺成清晰的“电路”。 OpenAI 此次并未采用常规的“训练后剪枝”(Post-training Pruning),而是追求原生稀疏(Native Sparsity)。 在数学上,要让矩阵稀疏,通常会使用 L1 正则化(让权重趋近于 0)。但 OpenAI 这次采用了更激进的 L0 范数约束。 • 科学定义: L0 范数表示向量中非零元素的个数。 • 实现机制: 在训练的 Loss 函数中直接加入强约束,迫使模型在学习特征时,必须以“最小连接数”为代价。这相当于给模型下了一道死命令:“如果你能用 2 根线传导信息,就绝不允许用 3 根。” 最终,这 0.4B 的模型中,99.9% 的连接断开,剩余的 0.1% 构成了特定的、固定的信息流通过路(Circuits)。 为了验证这套理论,OpenAI 进行了一项名为**“均值屏蔽剪枝”**的消融实验。他们以“Python 代码中的引号闭合”任务为例,试图寻找负责这一逻辑的最小单元。 在稠密模型中,这个功能可能分布在几千个神经元里。但在 Circuit Sparsity 模型中,研究人员提取出了一个令人震惊的极简电路: • 组成: 仅包含 2 个 MLP 神经元 和 1 个注意力头(Attention Head)。 • 分工: • Attention Head:负责“长距离关注”,在前文中寻找未闭合的引号。 • MLP Neuron A:作为“检测器”,当发现引号时激活。 • MLP Neuron B:作为“分类器”,决定下一个词应该是单引号还是双引号。 这是 AI 领域的一个里程碑时刻: 我们第一次从数学上证明了,大模型的复杂推理能力,可以被拆解为一个个充分且必要的微观电路。 • 充分性: 仅保留这 3 个节点,任务准确率 100%。 • 必要性: 只要切断这 3 个中的任意一个,任务处理能力瞬间归零。 数据显示,在预训练 Loss 相同的情况下,稀疏模型的任务专属电路规模比稠密模型小 16 倍。这意味着逻辑更纯粹,噪声更少。 我知道很多同行会问:“这不就是现在 GPT-4、Mistral 甚至 DeepSeek 都在用的 MoE 吗?” 必须澄清:这完全是两码事。 甚至可以说,Circuit Sparsity 是在底层逻辑上对 MoE 的一种“降维打击”。 MoE(Mixture of Experts)通过门控网络(Router)将输入分配给不同的“专家”模块。 • 缺陷一(宏观粗糙): MoE 的稀疏是**模块级(Block-level)**的。每个“专家”内部依然是稠密的黑箱。 • 缺陷二(同质化): 学术界发现,MoE 训练后期往往会出现“专家同质化”现象,也就是多个专家学到了类似的特征,知识冗余依然存在。 • 缺陷三(路由器黑箱): Router 本身也是一个神经网络,它的决策逻辑同样不可解释。 Circuit Sparsity 是**神经元级(Neuron-level)**的稀疏。 • 特征正交性: 它不需要 Router,而是通过高维投影和极度稀疏,强迫每个特征向量在空间上保持正交(Orthogonal)。 • 单义性(Monosemanticity): 理想状态下,这里的一个神经元,就只代表一个概念(例如“引号”、“愤怒”或“欺骗”)。 一句话总结:MoE 是让一群糊涂的专家分工干活;Circuit Sparsity 是致力于培养一个个思路极其清晰的独立工匠。 既然技术这么强,为什么没有马上取代 GPT-4?作为一线技术人,我们要看清硬币的背面。 这听起来反直觉,但**“训练稀疏模型”比“训练稠密模型”要贵得多**。 • 训练开销: 保持 L0 约束是一个极难的优化问题(NP-hard 问题的近似求解)。要在一个庞大的参数空间里找到那 0.1% 的黄金连接,计算量通常是训练同等规模稠密模型的 100 到 1000 倍。 • 硬件不友好: 现代 GPU(如 H100)是专门为稠密矩阵乘法设计的。在硬件层面处理随机稀疏的内存访问(Random Memory Access),效率极其低下。 尽管如此,OpenAI 的这项研究指明了 AI 的未来方向——可解释性安全(Interpretability Safety)。 我们预判未来会有两条技术路线: • 路线 A(工业界): 继续使用 MoE 扛负载,但利用 Circuit Sparsity 的思想,开发**“稀疏解码器”**,从已经训练好的大模型中提取关键电路,用于监控 AI 是否撒谎或产生危险念头。 • 路线 B(学术界): 攻克稀疏训练算法,从数学层面找到高效训练稀疏网络的方法(如 Lottery Ticket Hypothesis 的进阶版),最终造出原生可解释的通用人工智能。 Circuit Sparsity 的出现,意味着我们正在尝试拿回对 AI 的“知情权”。 在此之前,我们像是在炼丹——只要炉子里出来的药能治病就行。而现在,我们终于开始拿起显微镜,去分析每一个分子的结构。 虽然这 0.4B 的小模型现在看起来还很稚嫩,但它留下的那 0.1% 的连接,可能正是人类通往可信赖 AGI 的唯一桥梁。 你好,未来。
一、 房间里的大象:稠密模型的“黑箱”危机
1. 稠密矩阵的“多义性”诅咒

2. “叠加”假说
二、 硬核解析:Circuit Sparsity 如何重构神经网络?

1. L0 范数的暴力美学
2. 震撼实验:2个神经元的“代码逻辑”

三、 技术对决:Circuit Sparsity vs. MoE(混合专家模型)
1. MoE 的本质:为了计算效率的“伪稀疏”
 2. Circuit Sparsity 的本质:为了理解智能的“真稀疏”
2. Circuit Sparsity 的本质:为了理解智能的“真稀疏”四、 泼冷水与展望:为何我们还在用稠密模型?
1. 计算成本的悖论
2. 未来的两条路
五、 结语