别再从零训Mamba了,苹果告诉你直接从Transformer改装更划算
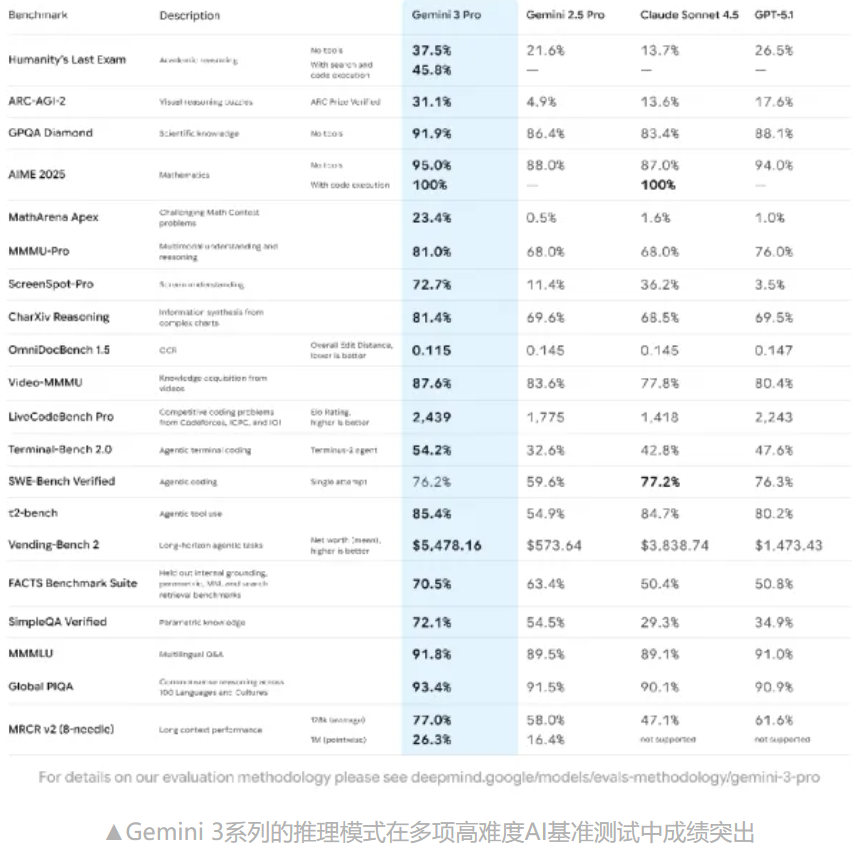
Transformer蒸馏Mamba不再是理论构想——苹果最新论文"Attention to Mamba"给出了一条可落地的两阶段蒸馏路径,把已训练好的Transformer模型转换为Mamba架构,将推理成本从O(n²)降至O(n),且困惑度仅从教师模型的13.86上升至14.11。
这意味着,现有的海量Transformer预训练资产不必推倒重来,而是可以通过"架构转制"实现系统性降本。本文将拆解这套方法的技术原理、实验数据与工程前景,帮助从业者判断这条路径的实际可行性。
Transformer推理成本为什么是"平方级"的痛点?
Transformer的注意力机制(Softmax Attention)在序列长度维度上具有O(n²)的计算复杂度,这是其推理成本高昂的根本原因。
当输入序列较短时(如数百token),这一开销尚可接受;但在长上下文场景——代码补全、多轮Agent对话、长文档推理——序列长度动辄数千乃至数万token,计算量和显存占用呈平方级增长,直接推高了部署成本。
具体而言,Softmax Attention需要为序列中的每个token计算与所有其他token的相关性得分,生成一个n×n的注意力矩阵。这一操作在训练阶段可以通过并行计算消化,但在推理阶段(尤其是自回归生成),每生成一个新token都需要重新计算与所有前文的关系,导致计算量随上下文窗口线性增长,总推理成本呈平方级。
过去几年,业界尝试了多种替代方案来解决这一问题:
这些方案的共同目标都是将推理成本降至线性级别,但要么在质量上与Transformer有明显差距,要么缺少大规模预训练模型的生态支撑。
为什么不能直接把Transformer蒸馏为Mamba?
直接从Transformer蒸馏到Mamba会导致性能严重崩塌——困惑度(PPL)可能从13.86飙升至100以上,几乎不可用。 这不是训练技巧的问题,而是两种架构在信息处理方式上的根本差异决定的。
Transformer的注意力机制允许模型在推理时"随时回看"任意位置的输入信息,类似于考试时可以翻阅笔记。而Mamba作为状态空间模型(SSM),采用递归方式逐步压缩历史信息到固定大小的隐状态中——更类似于闭卷考试,只能依赖记忆。
这种"信息访问模式"的差异意味着:如果直接用Transformer的输出分布去训练Mamba,学生模型需要同时学会两件事——新的信息压缩方式和原有的知识——而这两者之间的耦合会导致优化过程不稳定。据苹果论文"Attention to Mamba"(arXiv: 2604.14191)的消融实验,一步蒸馏的PPL直接炸到100以上,证实了这一路径的不可行性。
苹果的HedgeMamba方案:两阶段蒸馏的核心思路是什么?
苹果提出的核心创新是引入一个"中间形态"——先将Transformer转换为线性化Attention模型,再从线性化模型转换为Mamba——通过两步桥接绕过了直接蒸馏的性能崩塌问题。
这篇论文正式标题为"Attention to Mamba: A Recipe for Cross-Architecture Distillation",由Apple研究团队(Abhinav Moudgil, Ningyuan Huang等六位作者)于2026年4月提交至arXiv。
这一思路的精妙之处在于:每一步的架构差异都被控制在可管理的范围内,避免了"一步跨太大"导致的优化失败。
第一阶段:Softmax Attention → Hedgehog线性Attention
第一步的目标是将Transformer中计算昂贵的Softmax Attention替换为一种高质量的线性Attention,同时尽量保留原有性能。
传统线性Attention的核心问题在于无法模拟Softmax Attention的两个关键特性:低熵("尖锐")的注意力权重分布和点积单调性。这些特性使得Softmax Attention能够有效地聚焦于最相关的上下文信息。
为解决这一问题,苹果团队采用了Hedgehog方法(源自"The Hedgehog & the Porcupine"论文)。其核心思想是:依据Mercer定理,用一个小型多层感知器(MLP)学习一种特征映射函数,将查询(Query)和键(Key)映射到一个新的特征空间中,使得在该空间中的内积运算能够近似Softmax Attention的行为。
训练时,通过余弦相似度蒸馏将线性Attention的输出与原始Softmax Attention对齐。这一步完成后,得到一个计算复杂度为O(n)的"线性化Transformer",其行为与原始模型高度接近。
第二阶段:Hedgehog线性Attention → Mamba(HedgeMamba模块)
第二步将线性化Attention嵌入Mamba结构中,形成名为HedgeMamba的混合模块。
关键技术操作:
1. 参数映射初始化: 将线性Attention中的核心计算参数(Query-Key外积结构)直接映射到Mamba的SSM参数矩阵(A、B、C矩阵),使Mamba在初始化时行为就已接近前一阶段的线性Attention模型,而非从零开始学习 2. 归一化补偿: 原始Softmax Attention自带归一化(除以注意力权重之和),线性版本需要额外添加归一化步骤,以确保输出分布的稳定性 3. 能力解锁微调: 初始化完成后,重新启用Mamba原有的卷积和门控(Gate)机制,使用标准交叉熵损失对整个模型进行微调,让模型不只是模仿线性Attention,而是用Mamba的方式重新内化能力 4.
HedgeMamba的实验效果如何?性能究竟掉了多少?
在1B参数规模上,HedgeMamba仅使用约10B蒸馏token(约占教师模型训练数据的3.3%),就将困惑度控制在14.11——相比教师模型的13.86仅增加约1.8%。 这一结果远优于基线方法(Hedgehog线性Attention,PPL 14.89)和直接蒸馏(PPL > 100)。
困惑度对比
HedgeMamba Mamba 14.11 10B tokens
下游任务表现
论文在多个标准NLP基准上评估了HedgeMamba的迁移效果,截至2026年4月论文发布:
HedgeMamba在所有评估任务上全面超过Hedgehog基线,且整体表现已逼近教师模型Pythia-1B。 这说明保留下来的不只是表面的概率分布,而是相当一部分推理能力和语义结构。
训练成本
据论文披露,在8×A100 GPU节点上,蒸馏10B tokens的完整训练耗时约12天9小时。考虑到产出是一个性能接近教师模型的线性推理成本模型,这一训练投入是相当经济的。
消融实验揭示了哪些关键洞察?
消融分析确认了三个核心发现:门控机制是Mamba性能的关键、两阶段路径是结构性必要条件、蒸馏数据规模与性能呈正相关。
门控机制为什么如此重要?
架构消融实验表明,让Mamba在蒸馏后表现优异的关键不是简单堆叠模块,而是门控(Gate)机制。门控允许模型学习"该记住什么、该遗忘什么",对于从全局注意力转向递归压缩的架构转换至关重要。没有门控的Mamba变体在蒸馏后性能显著下降。
两阶段的数据分配策略
蒸馏的两个阶段(S1: Transformer→线性Attention;S2: 线性Attention→Mamba)之间的token分配比例对最终效果有显著影响。实验表明,最优策略是**"轻S1 + 重S2"**:
• 第一阶段主要完成表达方式对齐,所需数据量相对较少 • 第二阶段才是真正的能力迁移和内化阶段,需要更多训练数据 • 这表明中间表示只是过渡桥梁,核心价值在后半段的能力重建
数据规模的可扩展性
从1B到10B token的蒸馏实验中,性能随数据量稳定上升,没有出现不收敛或反复震荡的现象。这一点意义重大——它证明这条蒸馏路径具备可预测的规模化行为,而非只在特定数据量下碰巧有效。
这项研究对开源生态和企业降本意味着什么?
如果HedgeMamba的方法能稳定复现并扩展到更大规模,它将开启一种"模型转制"范式——过去几年积累的大量Transformer预训练模型,无需重新训练即可被转换为推理更高效的Mamba架构。
这一前景的工程意义可以从三个层面理解:
第一层:直接降本
Transformer的O(n²)推理复杂度转为Mamba的O(n),在长序列场景下意味着显存和计算成本的量级变化。对于需要处理长上下文的应用(代码助手、Agent系统、文档分析),这是实打实的成本压缩。
第二层:资产复用
当前开源社区(Hugging Face等平台)积累了数以千计的Transformer预训练模型。如果存在一条通用的"转制"路径,这些模型资产可以直接进入新的架构生态,无需从零预训练Mamba版本——这在时间和算力上都是巨大的节省。
第三层:行业趋势的佐证
截至2026年4月,业界已出现多个混合架构的落地案例:
这些案例表明,Transformer→SSM的架构迁移不再是学术探索,而正在成为产业级趋势。苹果的HedgeMamba为其中"无需重训的架构转换"这条路线提供了方法论基础。
当前方法的局限性与未来展望
HedgeMamba目前在1B参数规模上验证了可行性,但能否平滑扩展到7B、13B乃至更大规模仍有待验证。 同时,需要关注以下几个维度:
1. 规模上限: 论文实验基于Pythia-1B,更大规模的Transformer(如7B、70B)在蒸馏过程中可能出现新的优化挑战 2. 架构泛化: 当前方法针对标准Transformer和Mamba设计,对于Group Query Attention(GQA)、Mixture of Experts(MoE)等变体架构的适用性尚未验证 3. 任务泛化: 下游评估主要覆盖自然语言理解和推理任务,在代码生成、多模态等场景的表现需要进一步实验 4. 与Mamba-3的对比: 2026年3月发布的Mamba-3引入了复数值SSM和MIMO结构,在同等规模上超越了多个基线模型——如果将HedgeMamba与Mamba-3结合,可能释放更大潜力
常见问题(FAQ)
HedgeMamba和Mamba有什么区别?
HedgeMamba不是一个独立的模型架构,而是苹果论文"Attention to Mamba"中提出的一种混合模块名称。它特指通过Hedgehog线性Attention初始化的Mamba模块。最终蒸馏产物是一个标准的Mamba模型,只是在训练过程中使用了HedgeMamba作为中间桥梁。
两阶段蒸馏需要多少训练数据?
论文实验使用了约10B tokens进行蒸馏,约占教师模型(Pythia-1B,基于The Pile数据集300B tokens)训练数据的3.3%。训练在8×A100节点上耗时约12天9小时。
Hedgehog线性Attention是什么?
Hedgehog是一种高质量的线性Attention方法,源自论文"The Hedgehog & the Porcupine"。它使用一个小型MLP学习特征映射函数,使线性Attention能够模拟Softmax Attention的低熵权重分布和点积单调性,从而在保持O(n)复杂度的同时大幅缩小与Softmax Attention的质量差距。
这项技术适用于所有Transformer模型吗?
目前论文在Pythia-1B上验证了可行性,尚未在更大规模或不同架构变体(如GQA、MoE)上进行验证。理论上,该方法的核心原理(两阶段渐进式架构转换)具有通用性,但实际效果需要逐一验证。
蒸馏后的Mamba模型推理速度提升多少?
论文聚焦于架构转换的可行性和质量保留,未直接报告推理加速比。从理论复杂度看,Mamba的O(n)推理成本相比Transformer的O(n²)在长序列场景下可带来数倍至数十倍的加速,具体取决于序列长度和硬件配置。
和直接训练一个Mamba模型相比,蒸馏方案有什么优势?
核心优势在于复用已有Transformer的预训练知识,避免从零训练Mamba的高昂成本。直接训练一个同等质量的Mamba模型可能需要数百B tokens和数千GPU小时,而蒸馏仅需10B tokens即可获得接近教师水平的性能。