OpenAI提前发布GPT Image 1.5:速度提升四倍,局部编辑与细节保持大进化
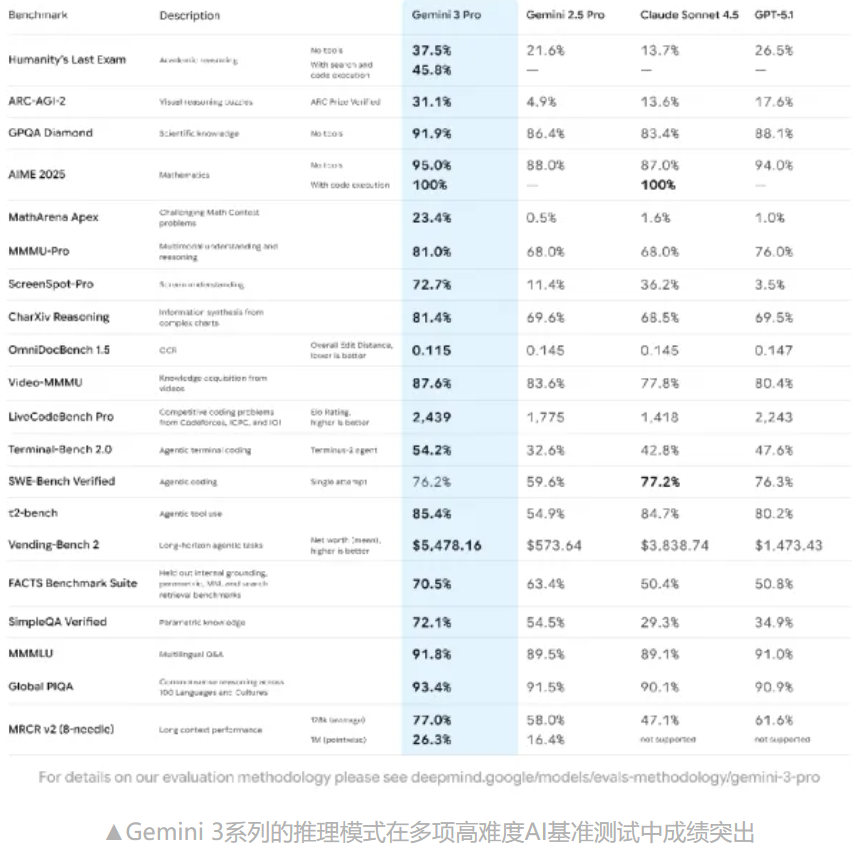
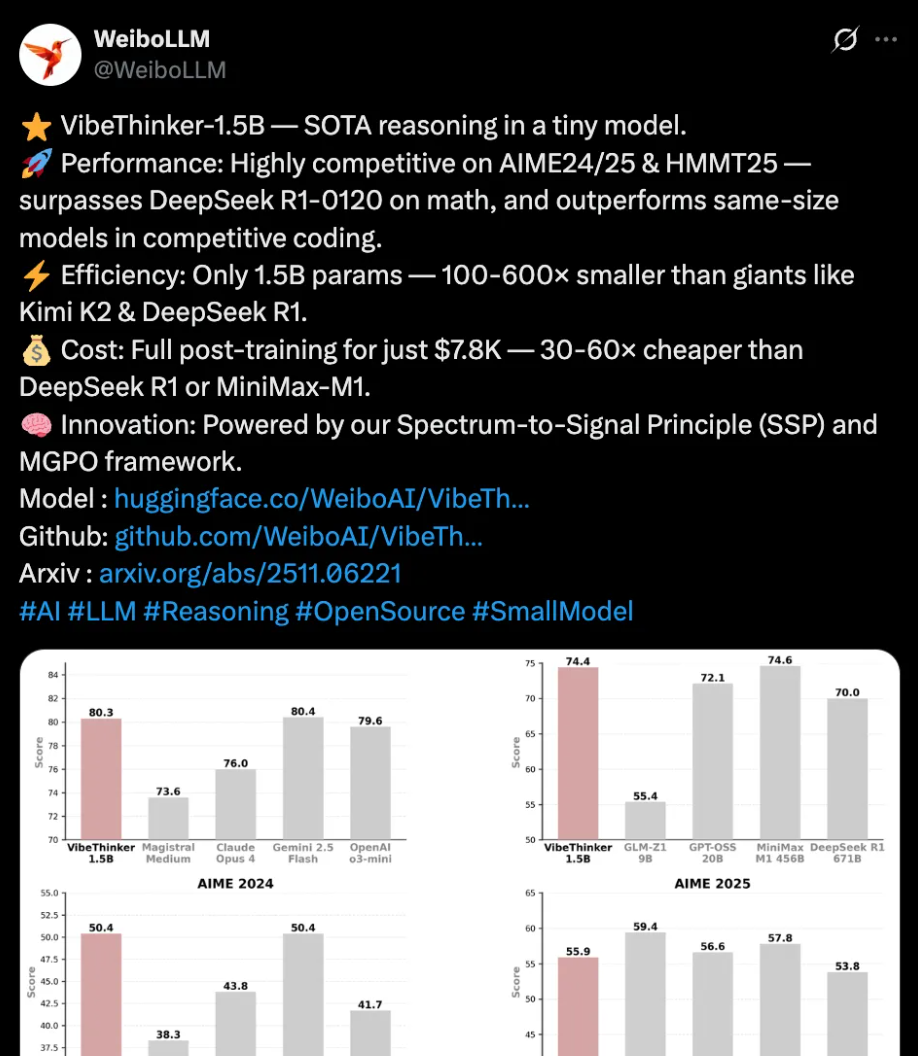
12 月 16 日,OpenAI 宣布推出全新的图像生成模型 —— GPT Image 1.5。这一更新比原计划提前了整整一个月,释放出十分明确的信号:在生成式 AI 的赛道上,争分夺秒已成为常态。 据多方消息,OpenAI 此次加快发布节奏,是在回应 Google 近期的多项新品发布,包括 Gemini 3 与 Nano Banana Pro 两款模型。在某些基准测试上,Google 模型表现出了明显的领先优势,这对 OpenAI 构成了直接的竞争压力。 有业内人士透露,Sam Altman 在内部发出了被称为 “code red” 的紧急备忘,要求团队压缩迭代周期,将更多产品提前投入市场,以扭转竞争态势。可以说,GPT Image 1.5 的提前亮相,是一场战略上的“加速冲刺”。 GPT Image 1.5 对用户输入的文本指令解析更加精准,不仅能抓住关键词,还能更好理解复杂要求,例如指定多个对象的相对位置、光线条件及背景细节。 在上一代模型中,局部修改常常会影响整幅画面的平衡。而在 GPT Image 1.5 中,局部编辑能更精确地锁定目标区域,比如仅调整人物的表情或背景的色调,却能不破坏原有构图。 速度的提升意味着等待时间显著缩短,从数十秒压缩到几秒以内。这对追求快速出图的设计师与营销团队极具吸引力。 与 Nano Banana Pro 对标,GPT Image 1.5 在保持光线、构图与色调稳定上有了明显提升。即使多次修改同一个场景,细节也能保持高度一致。 无论是添加新元素、移除不需要的部分,还是进行组合、混合、结构翻转,模型都能在不破坏原有图像特性的前提下完成。 在创意测试中,模型展现出很强的适应能力: • 电影海报设计:根据指定主题和主角风格快速生成高完成度的视觉稿。 • 文本渲染案例:制作“汉堡热量信息图”,模型能将大量小尺寸文字在图中保持清晰可读,同时确保布局与间距稳定。 • 历史场景复现:如 70 年代伦敦的公交车广告,通过调色和细节还原,实现高度写实的场景构建。 • 艺术风格创作:生成海洋生物题材的日系动漫海报,人物表情、光线氛围和背景细节都能稳定呈现,即便涉及多个面孔也不易失真。 在回顾初代模型的典型生成案例时,GPT Image 1.5 的画质与细节保持度有了显著提升,人物边缘更加清晰,色彩过渡自然。 但它并非毫无瑕疵——在极端复杂的场景和高度抽象的画面中,偶尔会出现元素比例不完全准确的问题。未来版本仍有优化的空间。 OpenAI 同步将 GPT Image 1.5 的所有改进开放给 API 用户,并将图像输入/输出的价格下调 20%。这使得在电商产品目录生成、品牌宣传设计和营销物料定制等领域,应用成本更低、产出效率更高。 一些设计平台的高管已表示,模型的高保真度输出和稳定构图能力能够与 Wix、Canva 等工具快速整合,从而提升面向企业或个人的创作服务品质。 在 ChatGPT 中,图像生成获得了独立入口,界面更像一个“创作工作室”。新版本支持更直观的查看与编辑:用户可以直接点击图像中的某一部分进行修改,或从热门提示词与预设滤镜中获得创作灵感。 此外,系统开始在 ChatGPT 的部分回答中融合更多可视化内容,使文字与图像更紧密结合,让创作过程更接近“所见即所得”。 GPT Image 1.5 的出现,不仅提升了图像生成的速度与质量,也体现了 OpenAI 缩短“从想法到成品”路径的长远愿景。 在竞争激烈的生成式 AI 市场中,这种加速迭代与体验优化,或许将进一步推动用户把更多创意直接落地为高质量的视觉作品。未来的创作,可能会变得更加自由和即时。一、市场背景与竞争压力

二、核心技术升级亮点
1. 更强的指令理解
2. 局部编辑精细化
3. 生成速度最高提升至 4 倍

4. 编辑一致性的突破
5. 支持更多复杂操作
三、功能演示与案例细节
四、性能评估与改进空间

五、API 与商业落地应用

六、用户界面革新与体验优化
七、总结与愿景